


💿 Record Labels Strike Back | TED AI Show ft. Therapy Bots | Quick Hits ft. Stability, OpenAI and Claude
Robots that make humans feel better. Record labels strike back. Video essay on Apple's AI strategy. Plus, weekly quick hits.

Hey Creative Technologists,
In this edition:
TED AI Show Ep 6: AI therapy is here. But what does it mean for you? w/ Dr. Alison Darcy (Founder of WoeBot)
Deep Dive: My thoughts on Suno/Udio lawsuits (and really any Gen AI model trained on ‘publicly available data’)
Video essay on Apple’s AI strategy ala. “AI for the rest of us”
AI quick hits (Stability AI changes, OpenAI CTO remarks, Claude 3.5)

AI therapy is here. But what does it mean for you? w/ Dr. Alison Darcy.
It was a pleasure speaking with Dr. Alison Darcy on The TED AI Show. She's a Stanford educated research psychologist, founder of Woebot, and a tech pioneer on the prestigious TIME100 AI list.

In this week’s episode of The TED AI Show, we get into:
Therapy robots: It’s easy to think that the complexities of the human mind can only be understood by other humans. Yet research on chatbots and psychology suggests non-human bots can actually help improve mental health.
Patient perspective: Not only did I speak with Dr. Darcy, but I also spoke with Brian Chandler, a WoeBot user, to learn what chatbots reveal about our inner lives and what they can (and can’t) do when it comes to emotional wellness.
Check it out on Episode 6: The TED AI Show — available wherever you get your podcasts (episode links to: Spotify, Apple, YouTube, everywhere else)
Deep Dive: Is training AI models on copyrighted material fair game?
Let's start by acknowledging that ‘publicly available data’ is a euphemism for scraping pretty much anything you can access via an internet browser – including YouTube videos, podcasts, and clearly commercial music libraries, and as a consequence pissing off record labels and celebrity artists.

The crux of the issue? What is ethical is not always legal, and what is legal is not always ethical.
Silicon Valley's Modus Operandi
"Our technology is transformative; it is designed to generate completely new outputs, not to memorize and regurgitate pre-existing content. That is why we don’t allow user prompts that reference specific artists," said Suno CEO Mikey Shulman in a statement.

In other words, this practice will absolutely continue until courts rule that training generative models on copyright material is not considered fair use, that the output is not transformative, and/or restrict it through a new regulatory framework.
Otherwise the Silicon Valley dictum applies: don’t bother asking for permission, ask for forgiveness later. Keep making the case that your usage is transformative, and then as your startup raises more captial, retroactively strike licensing deals with the parties whose content you trained on, much like OpenAI.
Of course, this doesn’t always work out as expected.
A single tweet by ScarJo unleashed a visceral shit storm upon OpenAI, ultimately resulting in the eerily similar voice of Sky being removed from ChatGPT. And this is despite OpenAI maintaining the voice wasn’t based on Scarlett, and was instead a voice actor, who for some strange reason is choosing to forgo the free publicity and remain anonymous. More than a little bit sus.

And of course, the New York Times is pushing on what could be a seminal lawsuit against OpenAI - making the case that OpenAI allegedly used its copyrighted articles without authorization to train AI models, which they claim diverts web traffic and reduces their subscription and advertising revenue.
Mixed Media Response
Now, NYT has the war chest to take on this legal battle. But most other media companies see the writing on the wall — and are taking their pennies on the dollar now, with some vague hope of harnessing AI to further feed the beast that is the modern attention economy.

It is thus unsurprising to see OpenAI strike licensing deals with the likes of NewsCorp, The Atlantic, Vox Media and ShutterStock. Similarly, Google and OpenAI are rumored to be forging deals with Hollywood studios. These deals would allow them to train their Veo and Sora video generation models on the studios' libraries of audio-visual umami.
The Music Industry's Dilemma
Suno and Udio on the music end will likely follow these bigger players. They'll probably strike licensing deals with record labels in the future. But the question is, does the music industry today feel threatened enough? Do they believe that generative AI music represents a clear and present danger to their roster of human artists?
In the short-form video era, spurred by the rise of TikTok, Instagram Reels and YouTube Shorts, the music industry struck a different kind of deal with these tech giants. They provided up to 60 second excerpts of their music, licensed with favorable terms. This made sense because these videos going viral with the song attached drove streams and sales for their music catalog.
Such is not the case for generative AI, where attribution is largely a feature relegated to search engine products like Perplexity, and pretty much nonexistent everywhere else – especially in audio/visual generation models, whether it’s Suno, Udio or DALL-E 3.
The Current Workaround
So in practice, startups and tech giants alike enforce a policy on the prompting and inference layer. Essentially, they continue to train models on copyrighted material, but they prevent users from putting in names of artist or copyrighted material in the final prompt.
So for instance, I can’t ask for a photo of Godzilla from DALL-E 3, but I can ask for a Kaiju monster that looks like a dinosaur, and I’d pretty much get the same thing.


If you want to be more sophisticated, you might run some classifier on the final output itself. You might say it looks too much like Mickey Mouse or <insert Disney IP>, and you might not share that generation with the user.
This opaquely forces the user to re-prompt (without any useful feedback) until they no longer trigger that classifier, and get some generations close to what they intended.
Some might argue this is a rather hypocritical stance by tech companies. After all, their neural nets are indeed trained on this copyrighted material. It's only crudely being prevented from generating such output.
But at that point of scrutiny, they've usually raised enough capital to license key parts of the training corpus needed to quell any legal action. Combined with public domain content, this is sufficient to unblock their product. That seems to be the strategy playing out before us, anyway.
The Real Losers
In all of this — it’s really the indie artist who is royally screwed. The creators who aren’t big enough to drive a collective bargaining effort with tech companies and get paid off for their content libraries.

I’m thinking of the millions of creatives who tirelessly uploaded content on YouTube, Instagram, Artstation, Soundcloud, Spotify, Substack, Medium, X, and beyond — whose work has been slurped into these gigantic training runs and infusing these neural networks with abilities we on social media deem to be 'magical!' All the while forgetting the faceless army who created the knowledge foundation — this proverbial library of Alexandria scrubbed of all author names.
So where does this leave us? We can be very sure that as long as courts don’t intervene - the practice of training on ‘publicly available data’ will continue. Robots.txt be damned. Copyright be damned. Proponents of this practice will say that we all learn from each other, and that “everything is a remix.”
Moving Beyond Human Limitations
But machines are very different from humans — a human can’t watch all of YouTube, can’t listen to every song on Spotify, can’t read all the text on the internet — but a machine can. And that makes it feel fundamentally different from a human learning from copyrighted material to produce transformative work.
Proponents will ask why machines should inherit the same limitations as humans? Why should they lobotomize the greatest record of human knowledge and creativity for outdated copyright law? And these are fine questions to ask, and I certainly won’t pretend to have all the answers.
But there’s one thing I feel strong about — no matter who produced the content, whether it’s a label-repped artist, YouTube creator, or a Substack writer — you’re at least entitled to an acknowledgement for your contribution to the greatest record of human knowledge and creativity.
So yes, perhaps it’s true that we shouldn’t infuse the limitations of humans into machines. It is also true that humans are incapable of outlining all of their influences — we assimilate them deeply, often unconsciously. But that's our flaw. Why should we settle for machines that possess the same shortcoming?
Video Essay: Apple Intelligence & Private AI
Apple’s big push into AI is here... but Elon is calling it “creepy spyware”. Is he justified? In this 20 min video I’ll dive into Apple's new AI strategy, uncovering the real privacy implications, and the impact of AI in our everyday lives.
AI Quick Hits
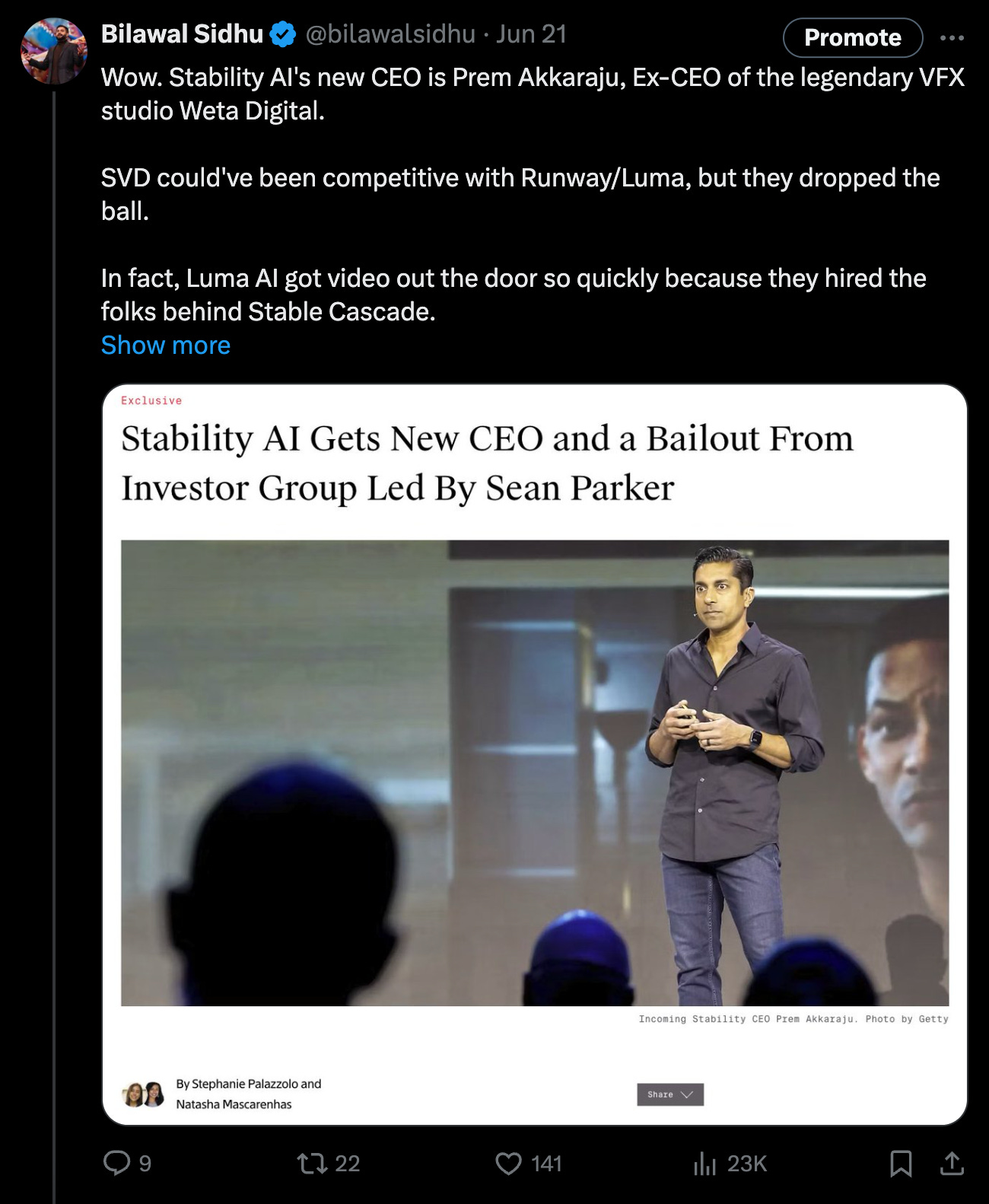
New Stability AI CEO - stability on the horizon?
The company that started the open source AI movement gets a bailout from an investor group led by Sean Parker, and a new CEO. Plus, scoop on how Luma AI got video out the door so quickly.

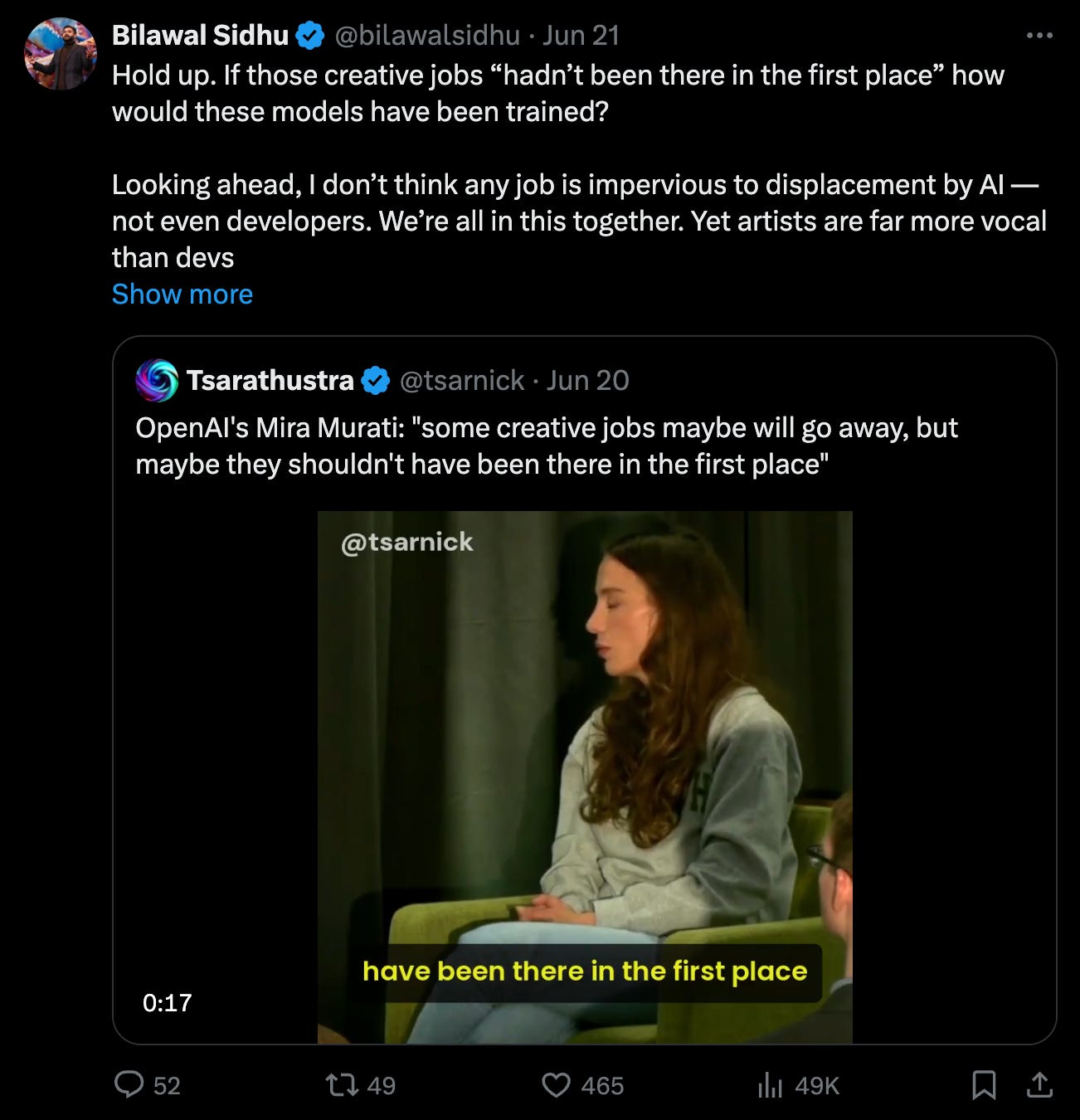
OpenAI CTO’s remarks — out of line or saying the quiet part out loud?
Mira’s take is viewed by many as saying the quiet part out loud — on the other hand it understates the sheer about of human effort that underlies the ‘intelligence’ of frontier models — whether it’s the training data, or armies overseas RLHF-ing these models. Watch it and dig into the comments:
Claude 3.5 Sonnet pretty much laps GPT-4o — time to switch, again
It's roughly 1/5th the price of Claude 3 Opus while being roughly 2x the speed — they’re clearly gunning for GPT-4o with a focus on efficiency:



That’s it for this edition. As always, hit me up with with thoughts, and I’ll see y’all in the next one!
Cheers,
Very insightful.